

Redis分布式缓存(一)
📢 本篇主要包含内容有:
- 缓存击穿(缓存失效)
- 缓存穿透(缓存删除)
- 基于
DCL机制解决突发热点缓存并发重建导致DB压力暴增 Redis分布式锁解决缓存与数据库数据不一致
1.分布式缓存的作用与各种问题
1.1 作用
分布式缓存主要解决的是单机缓存的容量受服务器限制并且无法保存通用的信息。因为,本地缓存只在当前服务里有效,比如如果你部署了两个相同的服务,他们两者之间的缓存数据是无法共同的。
以我平时写代码的感受来讲:
- 现在做项目很多都是前后端分离的模式,所以
session就无法使用了,需要使用Redis。 - 在对某一经常访问的内容,可以使用
Redis做缓存加快访问速度 - …
1.2 问题
虽然Redis对我们的网站很有用,但是使用不当也会存在很多并发安全问题。我们以一个简单springboot小案例的增删改查业务入手,逐步解决本篇开头提到的问题。
2. 初始化
2.1 导包(部分)
<!--Redis-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!--Redisson-->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.17.5</version>
</dependency>
<!--lombok-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<!--hutool-->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.5</version>
</dependency>
2.2 配置与注入
2.2.1 Redisson
@Bean
public Redisson redisson(){
// 单机模式
Config config = new Config();
config.useSingleServer().setAddress("redis://localhost:6379").setDatabase(0);
// 设置分布式锁watch dog超时时间
return (Redisson) Redisson.create(config);
}
2.2.2 其他配置
RedisConfig非重点,不做展示。
2.3 工具类
RedisUtil和JsonUtil非重点,不做展示。
2.4 初始代码
简介:
- 以下代码为对商品的增改和查的
Service层,在插入商品、更新商品和在缓存中未查询到而在数据库查询到商品时都会在Redis中设置缓存。- 在设置缓存时都设置了1天的过期时间,通过设置超时时间,避免所有数据加入缓存,解决海量数据问题。
- 缓存读延期,将热点数据长时间放入缓存,把海量数据冷热分离。
- 其他
Controller、Mapper和domain均为最常见的代码,这里限于篇幅就不做展示。问题:
- 以下代码存在严重的并发安全问题,如缓存击穿、缓存穿透、突发热点缓存并发重建导致DB压力暴增和缓存与数据库数据不一致,将在接下来的内容逐渐优化。
- …
@Service
public class ProductService {
@Autowired
private ProductMapper productMapper;
@Autowired
private Redisson redisson;
@Autowired
private RedisUtil redisUtil;
// 设置超时时间,避免所有数据加入缓存,解决海量数据问题
public static final Integer PRODUCT_CACHE_TIMEOUT = 60 * 60 * 24;
@Transactional
public Product create(Product productParam) {
productMapper.insert(productParam);
redisUtil.setEx(RedisKeyPrefixConstants.PRODUCT_CACHE + productParam.getId(), JsonUtil.obj2StringPretty(productParam),
PRODUCT_CACHE_TIMEOUT, TimeUnit.SECONDS);
return productParam;
}
@Transactional
public Product update(Product productParam) {
productMapper.updateById(productParam);
redisUtil.setEx(RedisKeyPrefixConstants.PRODUCT_CACHE + productParam.getId(), JsonUtil.obj2StringPretty(productParam),
PRODUCT_CACHE_TIMEOUT, TimeUnit.SECONDS);
return productParam;
}
public Product get(Long productId) {
Product product;
String key = RedisKeyPrefixConstants.PRODUCT_CACHE + productId;
// 从缓存获取,如果获得直接返回,否则再查询数据库
getProductFromCache(key);
// 查询数据库
product = productMapper.selectById(productId);
if (product != null) {
redisUtil.setEx(key, JsonUtil.obj2StringPretty(product),
PRODUCT_CACHE_TIMEOUT, TimeUnit.SECONDS);
}
return product;
}
/**
* 从Redis中查询
* @param productCacheKey key
* @return value
*/
public Product getProductFromCache(String productCacheKey) {
Product product = null;
String productStr = redisUtil.get(productCacheKey);
if (StrUtil.isNotBlank(productStr)) {
product = JsonUtil.string2Obj(productStr, Product.class);
// 缓存读延期,将热点数据长时间放入缓存,把海量数据做冷热分离
redisUtil.expire(productCacheKey, PRODUCT_CACHE_TIMEOUT, TimeUnit.SECONDS);
}
return product;
}
}
3. 缓存击穿(失效)
由于大批量缓存在同一时间失效可能导致大量请求同时穿透缓存直达数据库,可能会造成数据库瞬间压力过大甚至挂掉,对于这种情况我们在批量增加缓存时最好将这一批数据的缓存过期时间设置为一个时间段内的不同时间。
3.1 解决方案
将代码中的过期时间设置为一个时间段内的不同时间。
// 产生随机超时时间,解决缓存击穿问题
public Integer genProductCacheTimeout() {
return PRODUCT_CACHE_TIMEOUT + RandomUtil.randomInt(30) * 60;
}
3.2 不足
- 缓存穿透
- 突发热点缓存并发重建导致DB压力暴增
- 缓存与数据库数据不一致
- …
4. 缓存穿透
缓存穿透是指查询一个根本不存在的数据, 缓存层和存储层都不会命中, 通常出于容错的考虑, 如果从存储层查不到数据则不写入缓存层。
缓存穿透将导致不存在的数据每次请求都要到存储层去查询, 失去了缓存保护后端存储的意义。造成缓存穿透的基本原因有两个:
- 自身业务代码或者数据出现问题。
- 一些恶意攻击、 爬虫等造成大量空命中。
4.1 解决方案
-
缓存空对象
// 设置空缓存值,避免缓存穿透问题 public static final String EMPTY_CACHE = "{}"; // 给空缓存也设置随机过期时间 public Integer genEmptyCacheTimeout() { return RandomUtil.randomInt(60); }更新查询商品的
get方法。public Product get(Long productId) { Product product; String key = RedisKeyPrefixConstants.PRODUCT_CACHE + productId; // 从缓存获取,如果获得直接返回,否则再查询数据库 getProductFromCache(key); // 查询数据库 product = productMapper.selectById(productId); if (product != null) { redisUtil.setEx(key, JsonUtil.obj2StringPretty(product), genProductCacheTimeout(), TimeUnit.SECONDS); }else { // 设置空串,防止缓存穿透 redisUtil.setEx(key, EMPTY_CACHE, genEmptyCacheTimeout(), TimeUnit.SECONDS); } return product; }更新
getProductFromCache方法。/** * 从Redis中查询 * @param productCacheKey key * @return value */ public Product getProductFromCache(String productCacheKey) { Product product = null; String productStr = redisUtil.get(productCacheKey); if (StrUtil.isNotBlank(productStr)) { if (EMPTY_CACHE.equals(productStr)) { // 设置空串,防止缓存穿透 redisUtil.setEx(productCacheKey, EMPTY_CACHE, genEmptyCacheTimeout(), TimeUnit.SECONDS); return new Product(); } product = JsonUtil.string2Obj(productStr, Product.class); // 缓存读延期,将热点数据长时间放入缓存,把海量数据做冷热分离 redisUtil.expire(productCacheKey, genProductCacheTimeout(), TimeUnit.SECONDS); } return product; } -
布隆过滤器
- 待完成…
4.2 不足
- 突发热点缓存并发重建导致DB压力暴增
- 缓存与数据库数据不一致
- …
5. 突发热点缓存并发重建导致DB压力暴增
上面的代码已经解决了缓存击穿和缓存穿透问题,但如果以下两个问题同时出现,可能就会对应用造成致命的危害:
- 当前key是一个热点key(例如一个热门的娱乐新闻)并发量非常大。
- 重建缓存不能在极短时间内完成。
如果突然有大量线程来重建缓存,造成后端负载加大,甚至可能会让应用崩溃。要解决这个问题主要就是要避免大量线程同时重建缓存。
举个例子,如果一个有几亿粉丝的明星突然发了一个爆炸性的热点新闻,此时可能就会有成千上万的请求进行访问,而此时的缓存里还没有此热点的缓存,所以就会造成短时间内成千上万的没有缓存的请求打到数据库并且尝试建立此热点的缓存,给后端造成极大的负载,甚至让系统崩溃。
解决思路: 先只让第一个请求进入数据库进行查询,重建热点缓存,剩下的请求直接访问缓存即可。
5.1 DCL机制
双重检查锁定模式(DCL) 是一种软件设计模式用来减少并发系统中竞争和同步的开销。双重检查锁定模式首先验证锁定条件(第一次检查),只有通过锁定条件验证才真正的进行加锁逻辑并再次验证条件(第二次检查)。
体现在本案例中,就是先在锁的外部查询缓存,如果没查到进入锁内部后再次查询缓存,这样就能保证后面的请求在第一个请求缓存重建成功后能直接查询到缓存。
5.2 解决方案
-
synchronized,此方式是单机锁,只能控制一个Jvm进程,不适合分布式缓存,本篇不做介绍。 -
Redisson,分布式锁框架。// 分布式锁,根据id锁热点缓存重建 public static final String LOCK_PRODUCT_HOT_CACHE_CREATE_PREFIX = "lock:product:hot_cache_create:";- 更新查询商品的
get方法。
public Product get(Long productId) { Product product; String key = RedisKeyPrefixConstants.PRODUCT_CACHE + productId; // 从缓存获取,如果获得直接返回,否则再查询数据库 product = getProductFromCache(key); if (product != null) { return product; } // 分布式锁 RLock hotCacheCreateLock = redisson.getLock(LOCK_PRODUCT_HOT_CACHE_CREATE_PREFIX + productId); hotCacheCreateLock.lock(); // setnx(k,v) 加锁 try { // 双重检测锁,解决冷门商品突发性变成热点数据,导致数据库压力暴增 product = getProductFromCache(key); if (product != null) { return product; } // 查询数据库 product = productMapper.selectById(productId); /* ... 如果在这段时间内有其他线程执行了更新数据库操作,则会造成缓存与数据库数据不一致问题,所以需要加分布式锁 */ if (product != null) { redisUtil.setEx(key, JsonUtil.obj2StringPretty(product), genProductCacheTimeout(), TimeUnit.SECONDS); } else { // 设置空串,防止缓存穿透 redisUtil.setEx(key, EMPTY_CACHE, genEmptyCacheTimeout(), TimeUnit.SECONDS); } } finally { // 防止抛异常而无法释放锁 hotCacheCreateLock.unlock();// 删除锁 } return product; } - 更新查询商品的
5.3 不足
- 如果在查询数据库和设置缓存这段时间内有其他线程执行了更新数据库操作,则会造成缓存与数据库数据不一致问题,所以还需要加分布式锁。
- …
6. 缓存与数据库数据不一致
在大并发下,同时操作数据库与缓存会存在数据不一致问题
-
双写不一致
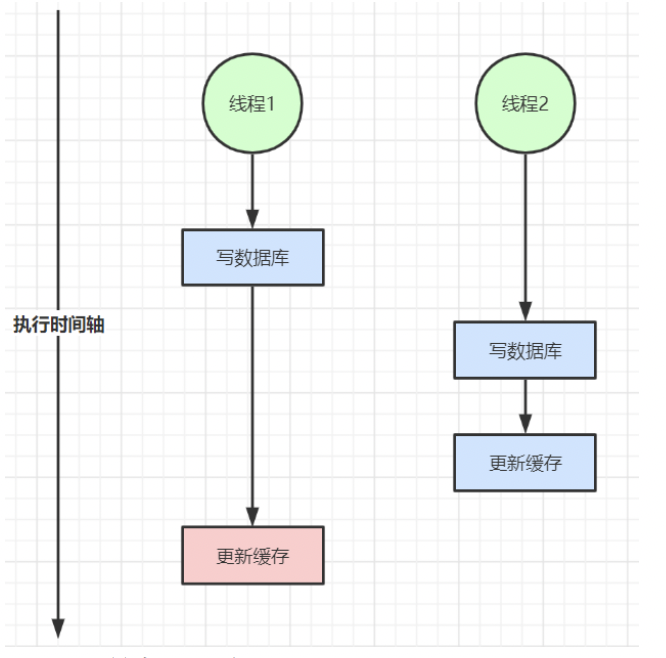
-
读写不一致
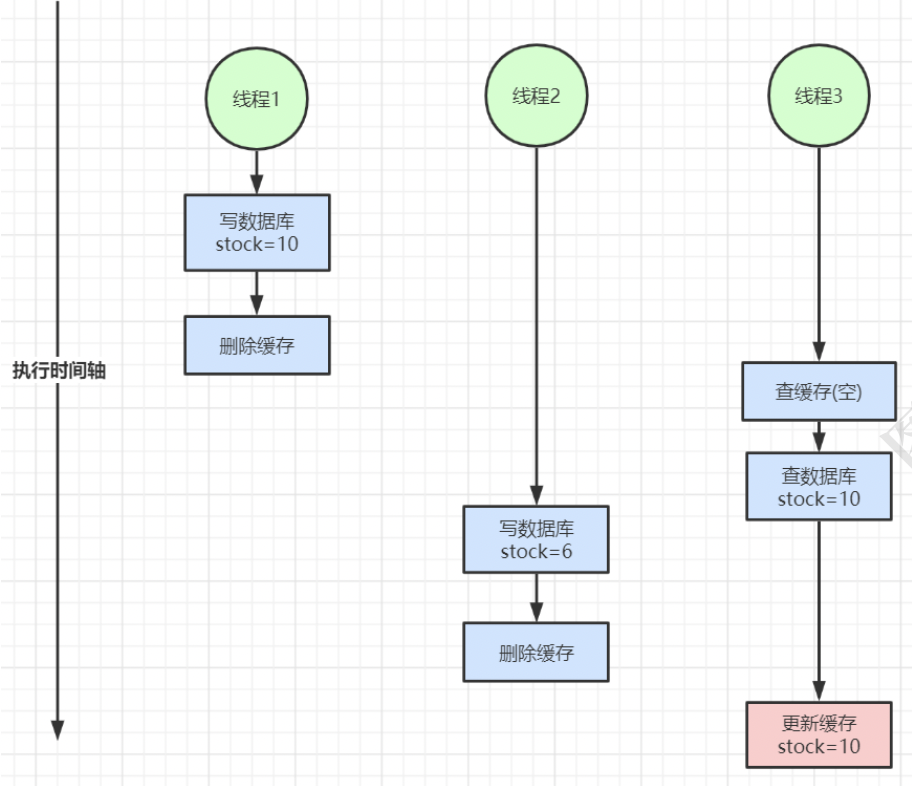
在实际生产环境中,绝大多数都是读多写少的情况。
解决思路: 通过加读写锁保证并发读写或写写的时候串行执行,读读的时候并行执行。
以上我们针对的都是读多写少的情况加入缓存提高性能,如果写多读多的情况又不能容忍缓存数据不一致,那就没必要加缓存了,可以直接操作数据库。当然,如果数据库抗不住压力,还可以把缓存作为数据读写的主存储,异步将数据同步到数据库,数据库只是作为数据的备份。
放入缓存的数据应该是对实时性、一致性要求不是很高的数据。切记不要为了用缓存,同时又要保证绝对的一致性做大量的过度设计和控制,增加系统复杂性!
6.1 解决
利用Redisson框架中的读写锁getReadWriteLock能够轻松实现。
// 分布式锁,保证数据库与缓存数据一致
public static final String LOCK_PRODUCT_UPDATE_PREFIX = "lock:product:update:";
-
更新查询商品的
get方法。public Product get(Long productId) { Product product; String key = RedisKeyPrefixConstants.PRODUCT_CACHE + productId; // 从缓存获取,如果获得直接返回,否则再查询数据库 product = getProductFromCache(key); if (product != null) { return product; } // 此处可做性能优化,需要估算请求执行时间(如2秒) // 还可将两处加锁合并,需要修改前面代码的逻辑 RLock hotCacheCreateLock = redisson.getLock(LOCK_PRODUCT_HOT_CACHE_CREATE_PREFIX + productId); hotCacheCreateLock.lock(); // setnx(k,v) 加锁 // 如果2秒后还未获得锁,可设定为直接查询缓存这样2秒后的请求就不用再加锁和释放锁 // 缺点是如果2秒后还没执行完,则缓存重建失败,大量请求会打入数据量,造成缓存击穿 // 如果能接受偶尔的缓存击穿,则可选择此优化方式 // hotCacheCreateLock.tryLock(2,TimeUnit.SECONDS); try { // 双重检测锁,解决冷门商品突发性变成热点数据,导致数据库压力暴增 product = getProductFromCache(key); if (product != null) { return product; } // 分布式锁,保证数据库与缓存数据一致 /*RLock updateProductLock = redisson.getLock(LOCK_PRODUCT_UPDATE_PREFIX + productId); updateProductLock.lock();*/ // 性能优化,读写锁,读能并行执行提高速度,读写操作串行执行保证数据一致 RReadWriteLock readWriteLock = redisson.getReadWriteLock(LOCK_PRODUCT_UPDATE_PREFIX + productId); RLock readLock = readWriteLock.readLock();// 读锁 readLock.lock(); try { // 查询数据库 product = productMapper.selectById(productId); /* ... 如果在这段时间内有其他线程执行了更新数据库操作,则会造成缓存与数据库数据不一致问题,所以需要加分布式锁 */ if (product != null) { // productMap.put(key,product); redisUtil.setEx(key, JsonUtil.obj2StringPretty(product), genProductCacheTimeout(), TimeUnit.SECONDS); } else { // 设置空串,防止缓存穿透 redisUtil.setEx(key, EMPTY_CACHE, genEmptyCacheTimeout(), TimeUnit.SECONDS); } } finally { /*updateProductLock.unlock();*/ readLock.unlock(); } } finally { // 防止抛异常而无法释放锁 hotCacheCreateLock.unlock();// 删除锁 } return product; }注意:
- 此代码还可做性能优化,在突发热点缓存并发重建的加锁机制可以尝试使用
tryLock方法,并设定时间(需估算如2秒)如果2秒后还未获得锁,可设定为直接查询缓存这样2秒后的请求就不用再加锁和释放锁,缺点是如果2秒后还没执行完,则缓存重建失败,大量请求会打入数据库,造成缓存击穿,如果能接受偶尔的缓存击穿可选择此优化方式。 - 还可将突发热点缓存并发重建的加锁和保证缓存与数据库一致的读写锁的加锁合并,则需要修改前面代码的逻辑。
- …
- 此代码还可做性能优化,在突发热点缓存并发重建的加锁机制可以尝试使用
-
更新修改商品的
update方法。@Transactional public Product update(Product productParam) { // 在更新数据库与缓存之间加入加入锁,保证缓存与数据库数据一致 /*RLock updateProductLock = redisson.getLock(LOCK_PRODUCT_UPDATE_PREFIX + productParam.getId()); updateProductLock.lock();*/ RReadWriteLock readWriteLock = redisson.getReadWriteLock(LOCK_PRODUCT_UPDATE_PREFIX + productParam.getId()); RLock writeLock = readWriteLock.writeLock(); writeLock.lock(); try { productMapper.updateById(productParam); // productMap.put(RedisKeyPrefixConstants.PRODUCT_CACHE + productParam.getId(),productParam); redisUtil.setEx(RedisKeyPrefixConstants.PRODUCT_CACHE + productParam.getId(), JsonUtil.obj2StringPretty(productParam), genProductCacheTimeout(), TimeUnit.SECONDS); } finally { /*updateProductLock.lock();*/ writeLock.unlock(); } return productParam; }
7. 总结
- 本篇研究了
Redis分布式缓存的应用,并且根据可能出现的问题,处理了缓存击穿、缓存穿透、突发热点缓存并发重建导致DB压力暴增和缓存与数据库数据不一致 。 - 待优化:在突发热点缓存并发重建的加锁机制可以尝试使用
tryLock方法;将突发热点缓存并发重建的加锁和保证缓存与数据库一致的读写锁的加锁合并。 - 待完成:缓存穿透的布隆过滤器、缓存雪崩问题、bigKey问题、多级缓存等…